Set
data contoh yang di gunakan adalah berkaitan uji kaji jenis makanan dan minuman
terhadap skor oleh pelajar-pelajar dalam matapelajaran berikut, Matematik,
Fizik, Kimia, Geografi dan Sejarah. Makanan yang di uji makanan berlauk daging
kambing dan satu lagi berlauk daging unta. Manakala, minuman yang di uji adalah
minuman kurma dan minuman madu. Analisa yang di gunakan adalah analisa MANOVA
dengan menggunakan SPSS.

Klik
pada Analyze, kemudian General Linear Model serta seterusnya Multivariate
seperti gambar rajah di atas.

Masukkan
pembolehubah-pembolehubah bersandar ke dalam kotak Dependent Variables
dan pembolehubah tidak bersandar atau pembolehubah bebas berkategori ke dalam Fixed
Factor(s).

Setelah
itu, klik pada Options.

Masukkan
maklumat daripada kotak kiri ke dalam Display Means for, kotak sebelah
kanan.

Klik
pada Descriptive statistics dan Homogeneity tests. Tekan pada Continue.
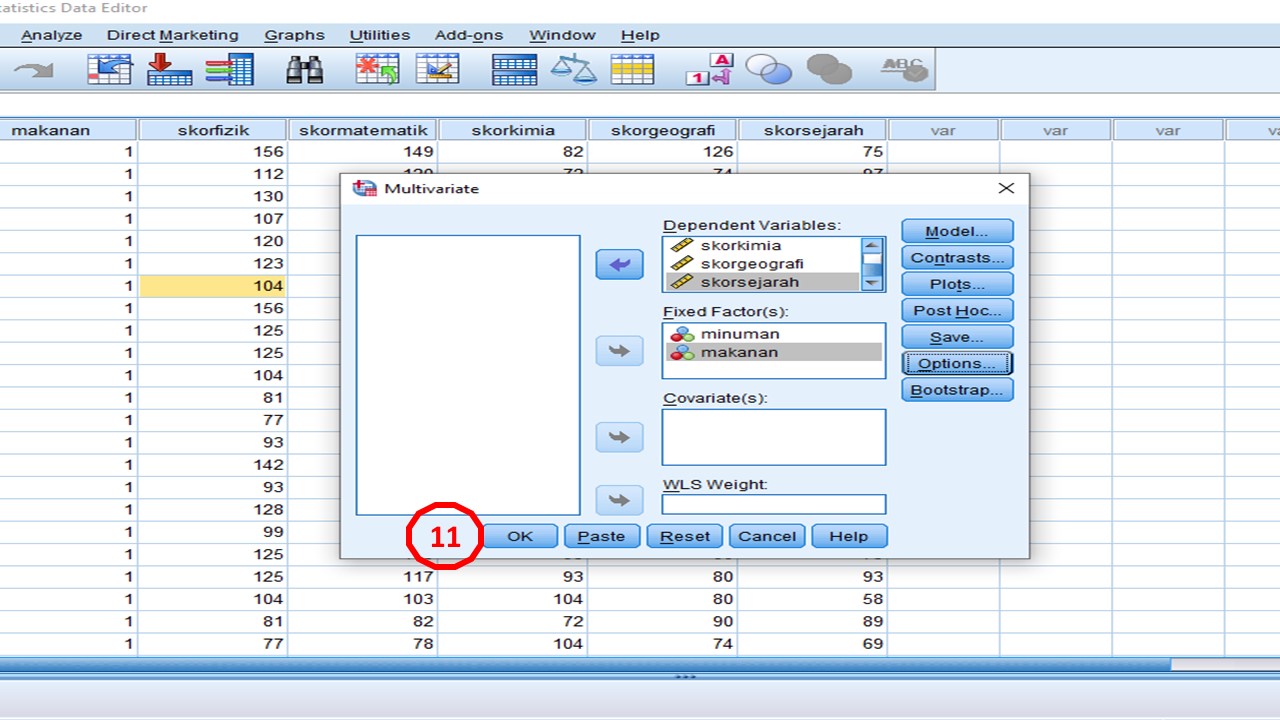
Klik
pada OK.

Seterusnya,
klik pada Graphs, kemudian Legacy Dialogs, sebelum menekan pada Line
seperti di atas.

Klik
pada Multiple serta klik pada Summaries of separate variables.
Kemudian klik pada Define.

Masukkan
pembolehubah bersandar ke dalam Lines Represent dan pembolehubah bebas
ke dalam Category Axis.

Kemudian
klik OK.

Ulang
semula langkah di atas tetapi dengan menggunakan pemboleh ubah bebas lain pula
kerana hanya satu pembolehubah bebas sahaja pada setiap masa. Jika sebelum ini
pembolehubah minuman, maka kali ini masukan pula pembolehubah makanan.


Melalui
jadual Descriptive Statistics di atas, maklumat seperti min, sisihan
piawai dan jumlah bilangan dalam subsample boleh di dapati.

Keputusan
ujian Box’s Test of Equality of Covariance Matrices menunjukan keputusan
tidak signifikan dengan nilai p yang lebih besar daripada 0.05 iaitu
0.081 (p > 0.05). Ini bermakna keputusan ujian di atas adalah,
terdapat kesamaan kovarians data bagi varians kelima-lima pembolehubah
bersandar merentasi kedua-dua pembolehubah bebas adalah sama dengan
populasinya. Ini memungkin penggunaan ujian MANOVA.

Keputusan
ujian Pillai’s Trace dalam jadual Multivariate Tests menunujukkan
bahawa wujud kesan utama pembolehubah bebas minuman dan makanan terhadap
kelima-lima pembolehubah bersandar iaitu skor Matematik, Fizik, Kimia, Geografi
dan Sejarah apabila nilai p kurang daripada 0.05 yang menjadikannya signifikan.
Bagi interaksi pula, nilai p adalah tidak signifikan, menunjukkan bahawa tidak
ada kesan interaksi di antara minuman*makanan terhadap pembolehubah bersandar.
Ini sekaligus membuktikan pembolehubah bebas memberi kesan terhadap pembolehubah
bersandar secara individu kerana ketiadaan kesan hasil interaksi kedua-dua
pembolehubah bebas.

Hasil
daripada analisa Levene’s Test of Equality of Error Variances, di dapati
tiga daripada lima pembolehubah bersandar adalah tidak signifikan, dengan nilai
p melebihi 0.05 dan hanya dua pembolehubah bersandar yang mempunyai nilai p
kurang daripada 0.05 sekaligus signifikan. Signifikan, menandakan varians antara
kategori dalam pembolehubah bersandar merentasi kategori-kategori dalam
pembolehubah bebas adalah sama.

Analisa
menunjukan kesan utama minuman wujud dengan nilai p kurang dariapad 0.05 iaitu
menanda terdapat hubungan serta kesan signifikan terhadap tiga pembolehubah
bersandar iaitu Fizik, Matematik dan Sejarah.
Manakala
bagi makanan, kesan utama di kesan terhadap Fizik, Matematik, Geografi dan
Sejarah.

R square
pula merupakan nilai yang menunjukkan sumbangan minuman dan makanan terhadap
Fizik sebanyak 25.3 (0.253) peratus, Matematik sebanyak 18.1 (0.181) peratus,
dan Sejarah sebanyak 30.6 (0.306) peratus.

Jadual
ini memaparkan keputusan perincian analisa min dan ralat piawai (std. error)
bersama dengan selang keyakinan 95%.
Secara
signifikan minuman madu mengatasi minuman kurma dalam skor Fizik, Matematik dan
Sejarah.

Makanan
berlauk kambing jelas mempunyai min yang signifikan lebih daripada makanan
berlauk unta dalam matapelajaran Fizik, Matematik, Geografi dan Sejarah.

Oleh
sebab tidak terdapat kesan interaksi di antara kedua-dua pembolehubah bebas,
maka perbezaan nilai min din antra kumpulan-kumpulan dalam setiap pembolehubah
bebas bagi kelima-lima matapelajaran mungkin di sebabkan oleh ralat persampelan
yang besar ( ini dapat di lihat pada ralat piawai yang agak besar)

Minuman
madu menunjukkan nilai min yang tinggi berbanding minuman kurma jika di lihat
pada garis skorfizik, skormatematik dan skorsejarah. Manakala skorkimia dan
skorgeografi seolah-seolah dalam keadaan melintang seperti tiada perbezaan pada
min.

Jelas
melalui graf di atas, skorfizik, skormatematik, skorgeografi dan skor sejarah,
menunjukan min yang tinggi di bahagian ‘makanan kambing’ manakala lebih rendah
pada ‘makanan unta’. Manakala, skorkimia perbezaannya tidak ketara dan
seolah-olah garis skorkimia dalam keadaan melintang, tidak menaik atau menurun.
- Bagi mendapatkan perkhidmatan Analisa Statistik boleh hubungi kami. Sila klik di sini untuk maklumat lanjut: https://mesrastats.blogspot.com/2014/06/data-analisa-data-entry-sem-spss-excel.html